|
|
||||||||||||
|
||||||||||||
|
Webmind
– a True
Digital Mind in the Making Ben Goertzel April 2001 AI – from
Vision to Reality
Artificial
intelligence is a burgeoning sub-discipline of
computer science these days. But it
almost entirely focuses on highly specialized problems constituting small
aspects of intelligence. “Real AI” –
the creation of computer programs with general intelligence, self-awareness,
autonomy, integrated cognition, perception and action – is still basically
the stuff of science fiction. But
it doesn’t have to be that way. In
our work at Webmind Inc. from 1997-2000, my colleagues and I transformed a
promising but incomplete conceptual and mathematical design for a real AI
into a comprehensive detailed software design, and implemented a large amount
of the code needed to make this design work.
At its peak, the team working on this project numbered 50 scientists
and engineers, spread across four continents. In
late March 2001, three and a half years after I and a group of friends
founded it, Webmind Inc. succumbed
to the bear market for tech
start-ups. But the core of the AI
R&D team continues working and is seeking funding to continue their
work. Assuming this funding is
secured, we believe we can complete the first-version Webmind – a program
that knows who and what it is, can hold intelligent conversations, and
progressively learns from its experiences in various domains -- within 9-24
months, depending on various factors.
Within
another couple years after that, we believe, we will be able to give the
program the ability to rewrite its own source code for improved intelligence,
thus setting up a trajectory of exponentially increasing software
intelligence that may well set the Singularity in motion big-time. This
is a bold claim, but it is not made unthinkingly, and we believe it
withstands scrutiny. Intelligent self-modification will not come for free,
even to a super-savvy AI Engine, but once we have built a general-purpose
learning system, there is no reason not to teach the system computer
programming and artificial intelligence theory. Indeed, in many ways these subjects will be easier for an intelligent
Internet software program to master than ideas like weather, sex and
politics, with which it will have no direct sensory contact. And once an AI Engine has
been taught how to optimize and improve simple software programs, there is
nothing stopping it from turning its ability upon itself. Each time it improves itself, its capacity
to improve itself will increase, yielding an exponential intelligence growth
curve. Granted, we don’t know what
the exponent of the curve will be – it will probably be years rather than
hours from the initiation of goal-oriented self-modification to the
achievement of superhuman intelligence.
But nonetheless, it is striking to realize how concretely we can now
envision this escalating intelligence trajectory. This
article gives an overview of Webmind – the philosophical and psychological
concepts underlying it, the broad outlines of the software design itself, and
how this AI program fits into the broader technological advances that
surround us, including the transformation of the Internet into a global brain
and the Singularity. Is AI
Possible? Not
everyone believes it’s possible to create a real AI program. There are several varieties to this
position, some more sensible than others.
First,
there is the idea that only creatures granted minds by God can possess
intelligence. This may be a common
perspective, but isn’t really worth discussing in a scientific context. More
interesting is the notion that digital computers can’t be intelligent because
mind is intrinsically a quantum phenomenon.
This is actually a claim of some subtlety, because David Deutsch has
proved that quantum computers can’t compute anything beyond what ordinary
digital computers can. But still, in
some cases, quantum computers can compute things much faster on average than
digital computers. And a few
mavericks like Stuart Hameroff and Roger Penrose have argued that
non-computational quantum gravity phenomena are at the core of biological
intelligence. Of course,
there is as yet no solid evidence of cognitively significant quantum
phenomena in the brain. But a lot of
things are unknown about the brain, and about quantum gravity for that
matter, so these points of view can’t be ruled out. My own
take on this is: Yes, it’s possible (though unproven) that quantum phenomena
are used by the human brain to accelerate certain kinds of problem
solving. On the other hand, digital
computers have their own special ways of accelerating problem solving, such
as super-fast, highly accurate arithmetic.
Another
even more cogent objection is that, even if it’s possible for a digital
computer to be conscious, there may be no way to figure out how to make such
a program except by copying the human brain very closely, or running a
humongously time-consuming process of evolution roughly emulating the
evolutionary process that gave rise to human intelligence. We don’t
have the neurophysiological knowledge to closely copy the human brain, and
simulating a decent-sized primordial soup on contemporary computers is simply
not possible. This objection to AI is
not an evasive tactic like the others, it’s a serious one. But I believe we’ve gotten around it, by
using a combination of psychological, neurophysiological, mathematical and
philosophical cues to puzzle out a workable architecture and dynamics for
machine intelligence. As mind
engineers, we have to do a lot of the work that evolution did in creating the
human mind/brain. An engineered mind
like Webmind will have some fundamentally different characteristics from an
evolved mind like the human brain, but this isn’t necessarily problematic
since our goal is not to simulate human intelligence but rather to create an
intelligent digital mind that knows it's digital and uses the peculiarities
of its digitality to its best advantage. The basic
philosophy of mind underlying Webmind work is that mind is not tied to any
particular set of physical processes or structures. Rather, “mind” is
shorthand for a certain pattern of organization and evolution of
patterns. This pattern of
organization and evolution can emerge from a brain, but it can also emerge
from a computer system. A digital
mind will never be exactly like a human mind, but it will manifest many of
the same higher-level structures and dynamics. To create a digital mind, one has to figure out what the
abstract structures and dynamics are that characterize “mind in general,” and
then figure out how to embody these in the digital computing substrate. We came
into the Webmind Inc. AI R&D project in 1997 with a lot of ideas about
the abstract structures and dynamics underlying mind and a simple initial
design for a computer implementation; now in 2001, after copious analysis and
experimentation, the mapping between mind structures and dynamics and
computational structures and dynamics is crystal clear. What is
“Intelligence”? Intelligence
doesn’t mean precisely simulating human intelligence. Webmind won’t ever do
that, and it would be unreasonable to expect it to, given that it lacks a
human body. The Turing Test -- “write
a computer program that can simulate a human in a text-based conversational
interchange” -- serves to make the theoretical point that intelligence is
defined by behavior rather than by mystical qualities, so that if a program
could act like a human, it should be considered as intelligent as a human.
But it is not useful as a guide for practical AI development. We don’t
have an IQ test for Webmind. The
creation of such a test might be an interesting task, but it can’t even be
approached until there are a lot of intelligent computer programs of the same
type. IQ tests work fairly well
within a single culture, and much worse across cultures – how much worse will
they work across species, or across different types of computer programs,
which may well be as different as different species of animals? What we
needed to guide our “real AI” development was something much more basic than
an IQ test: a working, practical understanding of the nature of intelligence,
to be used as an intuitive guide for our work. The
working definition of intelligence that I started out the project with builds
on various ideas from psychology and engineering, as documented in a number
of my academic research books. It was, simply, as follows: Intelligence is the ability to achieve
complex goals in a complex environment Webmind
work was also motivated by a closely related vision of intelligence provided
by Pei Wang,
Webmind Inc.’s first paid employee and Director of Research. Pei understands intelligence as, roughly
speaking, “the ability of working and adapting to the environment with
insufficient knowledge and resources.”
More concretely, he believes that an intelligent system is one that
works under the Assumption of Insufficient Knowledge and Resources (AIKR),
meaning that the system must be, at the ·
a
finite system --- the system's computing power, as well as its working and storage space, is limited; ·
a
real-time
system --- the tasks that the system has to process, including the
assimilation of new knowledge and the making of decisions, can emerge at any
time, and all have deadlines attached with them; ·
an
ampliative system --- the system not only can retrieve available knowledge
and derive sound conclusions from it, but also can make refutable hypotheses
and guesses based on it when no certain conclusion can be drawn ·
an
open system --- no restriction is imposed on the relationship between old
knowledge and new knowledge, as long as they are representable in the
system's interface language. ·
a
self-organized system --- the system can accommodate itself to new
knowledge, and adjust its memory structure and mechanism to improve its time
and space efficiency, under the assumption that future situations will be
similar to past situations. Obviously,
Pei’s definition and mine have a close relationship. My “complex goals in complex environments”
definition is purely behavioral: it doesn’t specify any particular
experiences or structures or processes as characteristic of intelligent
systems. I think this is as it should
be. Intelligence is something systems
display; how they achieve it under the hood is another story. On the
other hand, it may well be that certain structures and processes and
experiences are necessary aspects of any sufficiently intelligent
system. My guess is that the science
of 2050 will contain laws of the form: Any sufficiently intelligent system
has got to have this list of structures and has got to manifest this list of
processes. Of course,
a full science along these lines is not necessary for understanding how to
design an intelligent system. But we
need some results like this in order to proceed toward real AI today, and
Pei’s definition of intelligence is a step in this direction. For a real physical system to achieve
complex goals in complex environments, it has got to be finite, real-time,
ampliative and self-organized. It
might well be possible to prove this mathematically, but, this is not the
direction we have taken; instead we have taken this much to be clear and
directed our efforts toward more concrete tasks. Goals and
sub-goals So, then,
when I say that Webmind is an intelligent system, what I mean is that it is
capable of achieving a variety of complex goals in the complex environment
that is the Internet, using finite resources and finite knowledge. To go
beyond this fairly abstract statement, one has to specify something about
what kinds of goals and environments one is interested in. In the case of biological intelligence,
the key goals are survival of the organism and its DNA (the latter
represented by the organism’s offspring and its relatives). These lead to
sub-goals like reproductive success, status among one’s peers, and so forth,
which lead to refined cultural sub-goals like career success, intellectual
advancement, and so forth. In our
case, the goals that Webmind version 1.0 is expected to achieve are: 1.
Conversing
with humans in simple English, with the goal not of simulating human
conversation, but of expressing its insights and inferences to humans, and
gathering information and ideas from them. 2.
Learning
the preferences of humans and AI systems, and providing them with information
in accordance with their preferences.
Clarifying their preferences by asking them questions about them and
responding to their answers. 3.
Communicating
with other AI Engines, in a manner similar to its conversations with humans,
but using an AI-Engine-only language called KNOW. 4.
Composing
knowledge files containing its insights, inferences and discoveries,
expressed in KNOW or in simple English. 5.
Reporting
on its own state, and modifying its parameters based on its self-analysis to
optimize its achievement of its other goals. 6.
Predicting
economic and financial and political and consumer data based on diverse
numerical data and concepts expressed in news. Subsequent
versions of the system are expected to offer enhanced conversational fluency,
and enhanced abilities at knowledge creation, including theorem proving,
scientific discovery and the composition of knowledge files consisting of
complex discourses. And then of
course the holy grail: progressive self-modification, leading to
exponentially accelerating artificial superintelligence! These
lofty goals can be achieved step by step, beginning with a relatively simple
Baby Webmind and teaching it about the world as its mind structures and
dynamics are improved through further scientific study. Are these
goals complex enough that Webmind should be called intelligent? Ultimately this is a subjective
decision. My belief is, not
shockingly, yes. This is not a chess
program or a medical diagnosis program, which is capable in one narrow area
and ignorant of the world at large.
This is a program that studies itself and interacts with others, that
ingests information from the world around it and thinks about this
information, coming to its own conclusions and guiding its internal and
external actions accordingly. How smart
will it be, qualitatively? My sense
is that the first version will be significantly stupider than humans overall
though smarter in many particular domains; that within a couple years from
the first version’s release there may be a version that is competitive with
humans in terms of overall intelligence; and that within a few more years
there will probably be a version dramatically smarter than humans overall,
with a much more refined self-optimized design running on much more powerful
hardware. Artificial
superintelligence, step by step. (The Lack
of) Competitors in the Race to Real AI I’ve
explained what “creating a real AI” means to those of us on the Webmind AI
project: Creating a computer program
that can achieve complex goals in a complex environment – the goal of
socially interacting with humans and analyzing data in the context of the
Internet, in this case – using limited computational resources and in
reasonably rapid time. Another
natural question is: OK, so if AI is possible, how come it hasn’t been done
before? And how come so few people
are trying? Peter
Voss, a freelance AI theorist, entrepreneur and futurist whose ideas I like
very much, has summarized the situation as follows. Of all the people working in the field called AI: ·
80% don't believe in the concept of General Intelligence (but
instead, in a large collection of specific skills & knowledge) ·
of those that do, 80% don't believe its possible -- either
ever, or for a long, long time ·
of those that do, 80% work on domain-specific AI projects for
commercial or academic-politics reasons (results are a lot quicker) ·
of those left, 80% have the wrong conceptual
framework.... ·
And
nearly all of the people operating under basically correct conceptual
premises, lack the resources to adequately realize their ideas The
presupposition of the bulk of the work in the AI field is that solving
sub-problems of the “real AI” problem, by addressing individual aspects of
intelligence in isolation, contributes toward solving the overall problem of
creating real AI. While this is of
course true to a certain extent, our experience with Webmind suggests that it
is not so true as is commonly believed.
In many
cases, the best approach to implementing an aspect of mind in isolation is
very different from the best way to implement this same aspect of mind in the
framework of an integrated, self-organizing AI system. So who
else is actually working on building generally intelligent computer systems,
at the moment? Not very many groups. Without being too egomaniacal about it,
there is simply no evidence that anyone else has a serious and comprehensive design
for a digital mind. However we do
realize that there is bound to be more than one approach to creating real AI,
and we are always open to learning from the experiences of other teams with
similar ambitious goals. One
intriguing project on the real AI front is www.a-i.com,
a small Israeli company whose engineering group is run by Jason Hutchens, a
former colleague of mine from University of Western Australia in Perth. They are a direct competitor in that they
are seeking to create a conversational AI system somewhat similar to the
Webmind Conversation Engine. However,
they have a very small team and are focusing on statistical learning-based
language comprehension and generation rather than on deep cognition, semantics,
and so forth. Another
project that relates to our work less directly is Katsunori Shimohara and
Hugo de Garis’s Artificial
Brain project, initiated at ATR in Japan and continued at Starlab in Brussels and Genotype Inc. in
Boulder, Colorado. This is an attempt
to create a hardware platform (the CBM, or CAM-Brain Machine) for real AI
using Field-Programmable Gate Arrays to implement genetic programming evolution
of neural networks. Here the focus is
on the hardware platform, and there is not a well-articulated understanding
of how to use this hardware platform to give rise to real intelligence. It is highly possible that the CBM could
be used inside Webmind, as a special-purpose genetic programming component, A project
that once would have appeared to be competitive with ours, but changed its
goals well before Webmind Inc. was formed, is the well-known Cyc project. This began as an attempt to create true AI by encoding all
common sense knowledge in first-order predicate logic. They produced a somewhat useful knowledge
database and a fairly ordinary inference engine, but appear to have no
R&D program aimed at creating autonomous, creative interactive
intelligence. Underlying this work is
a very deep theory of logic-based knowledge representation and heuristic
intelligence, developed primarily by Doug Lenat.[1] Another
previous contender who has basically abandoned the race for true AI is Danny
Hillis, founder of the company Thinking Machines, Inc. This firm focused on the creation of an adequate
hardware platform for building real artificial intelligence – a massively
parallel, quasi-brain-like machine called the Connection Machine.[2] However,
as with DeGaris’s CBM approach, their pioneering hardware work was not
matched with a systematic effort to implement a truly intelligent program
embodying all the aspects of the mind.
The magnificent hardware design vision was not correlated with an
equally grand and detailed mind design vision. And at this point, of course, the Connection Machine hardware
has been rendered obsolete by developments in conventional computer hardware
and network computing. On the
other hand, Rodney Brooks’ well-known Cog project
at MIT is aiming toward building real AI in the long run, but their path
to real AI involves gradually building up to cognition after first getting
animal-like perception and action to work via “subsumption architecture
robotics.” This approach might
eventually yield success, but only after decades. Alan
Newell’s SOAR is another project
that once appeared to be grasping at the goal of real AI, but seems to have
retreated into a role of an interesting system for experimenting with limited-domain
cognitive science theories. Newell
tried to build “Unified Theories of Cognition”, based on ideas that have now
become fairly standard: logic-style knowledge representation, mental activity
as problem-solving carried out by an assemblage of heuristics, etc. The system was by no means a total
failure, but it was not constructed to have a real autonomy or
self-understanding. Rather, it’s a
disembodied problem-solving tool. But
it’s a fascinating software system and there’s a small but still-growing
community of SOAR enthusiasts in various American universities. Of course,
there are hundreds of other AI engineering projects in place at various
universities and companies throughout the world, but nearly all of these
involve building specialized AI systems restricted to one aspect of the mind,
rather than creating an overall intelligent system. The only
significant attempt to “put all the pieces together” would seem to have been
the Japanese 5th Generation Computer System project. But this project was doomed by its pure
engineering approach, by its lack of an underlying theory of mind. Few people mention this project these
days. The AI world appears to have
learned the wrong lessons from it – they have taken the lesson to be that
integrative AI is bad, rather than that integrative AI should be approached
from a sound conceptual basis. To build a
comprehensive system, with perception, action, memory, and the ability to
conceive of new ideas and to study itself, is not a simple thing. Necessarily, such a system consumes a lot
of computer memory and processing power, and is difficult to program and
debug because each of its parts gains its meaning largely from its
interaction with the other parts.
Yet, is this not the only approach that can possibly succeed at
achieving the goal of a real thinking machine? We now
have, for the first time, hardware barely adequate to support a comprehensive
AI system. Moore’s law and the
advance of high-bandwidth networking mean that the situation is going to keep
getting better and better. However,
we are stuck with a body of AI theory that has excessively adapted itself to
the era of weak computers, and that is consequently divided into a set of
narrow perspectives, each focusing on a particular aspect of the mind. In order to make real AI work, I believe,
we need to take an integrative perspective, focusing on ·
The
creation of a “mind OS” that embodies the basic nature of mind and allows
specialized mind structures and algorithms dealing with specialized aspects
of mind to happily coexist ·
The
implementation of a diversity of mind structures and dynamics (“mind
modules”) on top of this mind OS ·
The
encouragement of emergent phenomena produced by the interaction/cooperation of
the modules, so that the system as a whole is coherently responsive to its
goals This is
the core of the Webmind vision. It is
backed up by a design and implementation of the Mind OS, and a detailed
theory, design and implementation for a minimal necessary set of mind
structures and dynamics to run on top of it. The Psynet Model
of Mind
So let’s
cut to the chase. Prior to the
formation of Webmind Inc., inspired by Peirce, Nietzsche, Leibniz and other
philosophers of mind, I spent many years of my career creating my own
ambitious, integrative philosophy of mind.
After years searching for a good name, I settled for “the psynet
model” instead – psy for mind, net for network. Of all the
philosophical work I studied prior to forming my own theory of mind, perhaps
the most influential was that of Charles S. Peirce. Never one for timid formulations, he declared that: Logical
analysis applied to mental phenomena shows that there is but one law of mind,
namely, that ideas tend to spread continuously and to affect certain others
which stand to them in a peculiar relation of affectability. In this
spreading they lose intensity, and especially the power of affecting others,
but gain generality and become welded with other ideas. This is an
archetypal vision of mind that I call "mind as relationship" or
"mind as network." In
modern terminology, Peirce's "law of mind" might be rephrased as
follows: "The mind is an associative memory network, and its dynamic
dictates that each idea stored in the memory is an active agent, continually
acting on those other ideas with which the memory associates it." Others
since Peirce have also viewed the mind as a self-organizing network of
course. Marvin Minsky has famously
conceived it as a “society” and theorized about the various social
mind-agents that cooperate to form intelligence.[3] There is a whole branch of computer
science called “agent systems,” although most of this work pertains to agents
interacting economically or in simple collective problem-solving contexts,
rather than systems of agents cooperating to yield emergent intelligence.[4] My view of
the mind as an agent system is different from these in a number of ways, most
of which have to do with the impact of the emerging discipline of “complex
systems science” on my thinking.[5] My focus is not only on agent
interactions, and not only on the properties of individual agents, but on the
particular emergent structures that arise from the interactions of particular
types of agents – mental complexity, mental emergence, mental
self-organization. According
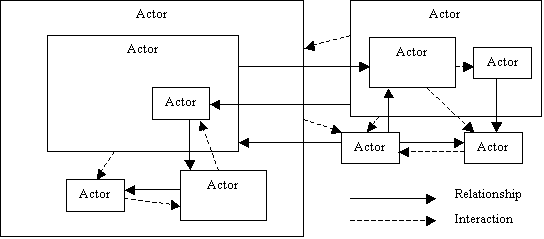
to the psynet model of mind: 1.
A
mind is a system of agents or "actors" (our currently preferred
term) which are able to transform, create and destroy other actors 2.
Many
of these actors act by recognizing patterns in the world, or in other actors;
others operate directly upon aspects of their environment 3.
Actors
pass attention ("active force") to other actors to which they are
related 4.
Thoughts,
feelings and other mental entities are self-reinforcing, self-producing,
systems of actors, which are to some extent useful for the goals of the
system 5.
These
self-producing mental subsystems build up into a complex network of
attractors, meta-attractors, etc. 6.
This
network of subsystem and associated attractors is "dual network" in
structure, i.e., it is structured according to at least
two principles: associativity (similarity and generic association) and
hierarchy (categorization and category-based control). 7.
Because
of finite memory capacity, mind must contain actors able to deal with
"ungrounded" patterns, i.e., actors which were formed from
now-forgotten actors, or which were learned from other minds rather than
first hand – this is called "reasoning."
(Of course, forgetting is just one reason for abstract or “ungrounded” 8.
A
mind possesses actors whose goal is to recognize the mind as a whole as a
pattern – these are "self."
System of Actors having
relationships one with others and performing interactions one onto another. According
to the psynet model, at bottom, the mind is a system of actors
interacting with each other, transforming each other, recognizing patterns in
each other, creating new actors embodying relations between each other. Individual actors may have some
intelligence, but most of their intelligence lies in the way they create and
use their relationships with other actors, and in the patterns that ensue
from multi-actor interactions. We need
actors that recognize and embody similarity relations between other actors,
and inheritance relations between other actors (inheritance meaning that one
actor in some sense can be used as another one, in terms of its properties or
the things it denotes). We need
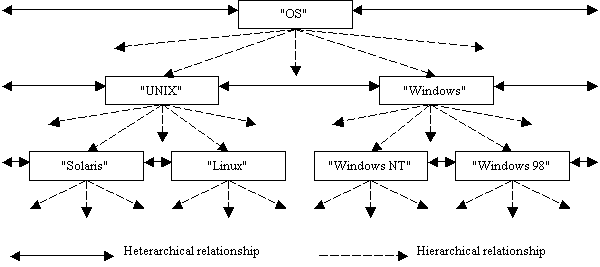
actors that recognize and embody more complex relationships This swarm
of interacting, intercreating actors leads to an emergent hierarchical
ontology, consisting of actors generalizing other actors in a tree; it also
leads to a sprawling network of interrelatedness, a “web of pattern” in which
each actor relates to some others. The balance between the hierarchical and heterarchical
(associational) emergent network of actor interrelations is crucial to the
mind.
Dual network of actors involving hierarchical and
heterarchical relationships. The overlap
of hierarchy and heterarchy gives the mind a kind of “dynamic library card
catalog” structure, in which topics are linked to other related topics
heterarchically, and linked to more general or specific topics
hierarchically. The creation of new
subtopics or supertopics has to make sense heterarchically, meaning that the
things in each topic grouping should have a lot of associative, heterarchical
relations with each other. Macro-level
mind patterns like the dual network are built up by many different actors;
according to the natural process of mind actor evolution, they’re also
“sculpted” by the deletion of actors.
All these actors recognizing patterns and creating new actors that
embody them – this creates a huge combinatorial explosion of actors. Given the finite resources that any real
system has at its disposal, forgetting is crucial to the mind – not every
actor that’s created can be retained forever. Forgetting means that, for example, a mind can retain the
datum that birds fly, without retaining much of the specific evidence that
led it to this conclusion. The generalization "birds fly" is a
pattern A in a large collection of observations B is retained, but the
observations B are not. Obviously,
a mind's intelligence will be enhanced if it forgets strategically, i.e.,
forgets those items which are the least intense patterns. And this ties in with the notion of mind
as an evolutionary system. A system
which is creating new actors, and then forgetting actors based on relative
uselessness, is evolving by natural selection. This evolution is the creative
force opposing the conservative force of self-production, actor
intercreation. Forgetting
ties in with the notion of grounding.
A pattern X is "grounded" to the extent that the mind
contains entities in which X is in fact a pattern. For instance, the pattern "birds fly" is grounded to
the extent that the mind contains specific memories of birds flying. Few
concepts are completely grounded in the mind, because of the need for drastic
forgetting of particular experiences.
This leads us to the need for "reasoning," which is, among
other things, a system of transformations specialized for producing
incompletely grounded patterns from incompletely grounded patterns.[6] Consider,
for example, the reasoning "Birds fly, flying objects can fall, so birds
can fall." Given extremely complete groundings for the observations
"birds fly" and "flying objects can fall", the reasoning
would be unnecessary – because the mind would contain specific instances of birds
falling, and could therefore get to the conclusion "birds can fall"
directly without going through two ancillary observations. But, if specific
memories of birds falling do not exist in the mind, because they have been
forgotten or because they have never been observed in the mind's incomplete
experience, then reasoning must be relied upon to yield the conclusion. The
necessity for forgetting is particularly intense at the lower levels of the
system. In particular, most of the patterns picked up by the
perceptual-cognitive-active loop are of ephemeral interest only and are not
worthy of long-term retention in a resource-bounded system. The fact that
most of the information coming into the system is going to be quickly
discarded, however, means that the emergent information contained in
perceptual input should be mined as rapidly as possible, which gives rise to
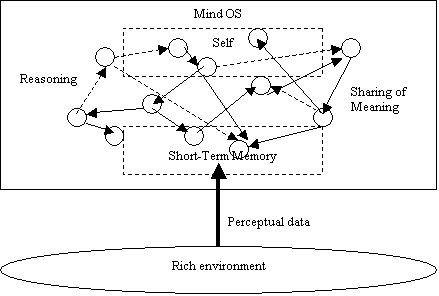
the phenomenon of "short-term memory."[7] What is
short-term memory? A mind must
contain actors specialized for rapidly mining information deemed highly
important (information recently obtained via perception, or else identified
by the rest of the mind as being highly essential). This is "short term memory “, a space within the mind
devoted to looking at a small set of things from as many different angles as
possible. The things contained in
short-term memory are grouped together in many different ways, experimentally
and fluidly. Because of this,
short-term memory can’t be all that capacious – there is a potential
“combinatorial explosion” problem in that N things can be grouped together in
2n ways. Human short-term memory is
commonly said to have a capacity of 7 +/- 2.
There are many subtleties in interpreting this number, which I won’t
go into here, but at very least it should be taken as an indication that the
percentage of the mind in the short-term memory is a very small one. From what
I’ve said so far, the psynet model is a highly general theory of the nature
of mind. Large aspects of the human mind, however, are not general at all,
and deal only with specific things, such as recognizing visual forms, moving
arms, etc. This is not a peculiarity of humans but
a general feature of intelligence.
The generality of a transformation may be defined as the variety of
possible entities that it can act on; and in this sense, the actors in a mind
will have a spectrum of degrees of specialization, frequently with more
specialized actors residing lower in the hierarchy. In particular, a mind must contain
procedures specialized for perception and action; and when specific
procedures are used repeatedly, they may become “automatized,” Another thing
that actors specialize for is communication. Linguistic communication is
carried out by stringing together symbols over time. It is hierarchically
based,
in that the symbols are grouped into categories, and many of the properties
of language may be understood by studying these categories. More specifically, the syntax of a
language is defined by a collection of categories, and "syntactic
transformations" mapping sequences of categories into categories.
Parsing is the repeated application of syntactic transformations. Language production is the reverse
process, in which categories are progressively expanded into sequences of
categories. Semantic transformations
map structures involving semantic categories and particular words or phrases
into actors representing generic relationships like similarity and
inheritance. They take structures in
the domain of language and map them into the generic domain of mind. And
language brings us to the last crucial feature of mind: self and
socialization. Language is used for
communicating with others, and the structures used for semantic understanding
are largely social in nature (actor, agent, and so forth). Language
is also used purely internally to clarify thought, and in this sense
it’s a projection of the social domain into the individual. Communicating about oneself via words or
gestures is a key aspect of building oneself. The
"self" of a mind (not the “higher self” of Eastern religion, but
the “psychosocial” self) is a poorly grounded pattern in the mind's own past.
In order to have a nontrivial self, a mind must possess The self is useful for guiding the
perceptual-cognitive-active information-gathering loop in productive
directions. Knowing its own holistic strengths and weaknesses, a mind can do
better at recognizing patterns and using these to achieve goals. The presence
of other similar beings is of inestimable use in recognizing the self. One models one's self on a combination of:
what one perceives internally, the external consequences of actions,
evaluations of the self given by other entities, and the structures one
perceives in other similar beings. It would be possible to have self
without society, but society makes it vastly easier, by leading to syntax
with its facility at mapping grounded domains into ungrounded domains, by
providing an analogue for inference of the self, by external evaluations fed
back to the self, and by the affordance of knowledge bases Clearly
there is much more to mind than all this – as we’ve learned over the last few
years, working out the details of each of these points uncovers a huge number
of subtle issues. But, even without
further specialization, this list of points does say something about AI. It dictates, for example, that ·
an
AI system must be a dynamical system, consisting of entities (actors) which
are able to act on each other (transform each other) in a variety of ways,
and some of this dynamical system must be sufficiently flexible to enable the
crystallization of a dual network structure, with emergent, synergetic
hierarchical and heterarchical subnets ·
this
dynamical system must contain a mechanism for the spreading of attention in
directions of shared meaning ·
this
dynamical system must have access to a rich stream of perceptual data, so as
to be able to build up a decent-sized pool of grounded patterns, leading
ultimately to the recognition of the self ·
this
dynamical system must contain entities that can reason (transfer information
from grounded to ungrounded patterns) ·
this
dynamical system must be contain entities that can manipulate categories (hierarchical
subnets) and transformations involving categories in a sophisticated way, so
as to enable syntax and semantics ·
this
dynamical system must recognize symmetric, asymmetric and emergent meaning
sharing, and build meanings using temporal and spatial relatedness, as well
as relatedness of internal structure, and relatedness in the context of the
system as a whole ·
this
dynamical system must have a specific mechanism for paying extra attention to
recently perceived data ("short-term memory") ·
this
dynamical system must be embedded in a community of similar dynamical
systems, so as to be able to properly understand itself ·
this
dynamical system must act on and be acted on by some kind of reasonably rich
world or environment. It is
interesting to note that these criteria, while simple, are not met by any
previously designed AI system, let alone any existing working program. Webmind strives to meet all these
criteria. What about
Consciousness? Finally, before
moving on to the nitty-gritty details of digital mind design, one more issue
must be addressed. What about
consciousness? The reader with a
certain philosophical cast of mind may react to the above list of criteria
for real AI as follows: “Sure … I can
believe a computer program can solve hard problems, and maybe even generalize
its problem-solving ability across domains.
But still … even so … it can’t be conscious, it can’t really feel and
experience, it can’t know that it is.” This is a
valid objection, which opens up an interesting topic, and I don’t want to
dismiss it glibly, but neither in this brief article can I do it
justice. My own view is that the word
“consciousness” wraps up a complex bundle of disparate meanings. For
instance, on the one hand there is the “cold” or cognitive aspect to
consciousness, which is a certain set of mind structures relating perception,
action and memory – this is what psychologists like to call “attention” these
days. Attention can be empirically
studied in humans, and the structures underlying human attention can be
embodied in software, at various levels of abstraction. As will be noted below, in designing Webmind, we
have carefully studied what is known about the structures and dynamics
underlying human attention. On the
other hand, there is the “hot” or experiential aspect of consciousness, which
is addressed extensively in Chinese and Indian philosophy, and is ultimately
not a scientific notion, but more of a human, subjective notion. Whether to consider another human or
another computer program conscious in this sense is really more of an
existential decision than a scientific one.
Stone Age man habitually These
comments are not intended to denigrate the importance of experience, of
awareness, of “hot” consciousness. In
the early days of the creation of the Webmind AI design, introspective
analysis and observation of the workings of my own consciousness played a
very major role (although, of course, I was always aware that this approach
has a strong potential to mislead and must be mediated by various types of
empirical study). Because of this, the psynet model of
mind bears a strong resemblance to the statements of various mystical
philosophers about the way the mind feels.[10] From a scientific point of view, though, this
is not the sort of thing one can argue about, one can prove or disprove; it
falls more into the category of conceptual background and inspiration. A discussion of the psynet model of mind
from the perspective of consciousness and spirituality can be found in the
rough-draft manuscript The
Unification of Science and Spirit. The Mind
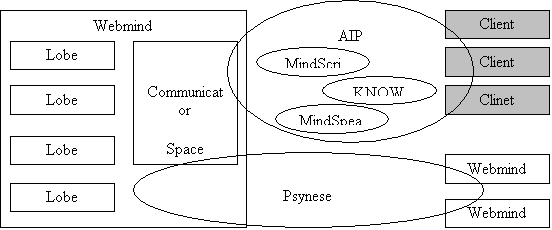
OS Webmind
embodies the psynet model of mind by
creating a “self-organizing actors OS” (“Mind OS”), a piece of software that
we call the Webmind Core, and then creating a large number of special types
of actors running on top of this.
Link actors, which embody relationships between Nodes (similarity, logical
inheritance or implication, data flow, etc.); Stimulus actors that spread
attention between Nodes and Links; Wanderer actors that move around between
Nodes building Links. These
general types of actors are then specialized into 100 or so node types Each actor
in the whole system is viewed as having its own little piece of
consciousness, its own autonomy, its own life cycle
Self-organizing Actors OS, relying on perceptual data coming through
Short Term Memory, translated into system patterns. In turn, these patterns are subjects of meaning sharing
and reasoning driven by system dynamics toward emergence of Self
There
are a number of special languages that the MindOS uses to talk to other software
programs. This kind of communication
is
Communications
between Webmind, its clients and other Webminds
Architecture of Webmind
On
top of the Mind OS, we’re building a large and complex software system, with many
different macro-level parts, most (but not quite all) based on the same
common data structures and dynamics, and interacting using the Mind OS’s
messaging system, and controlled overall using the Mind OS’s control
framework. The
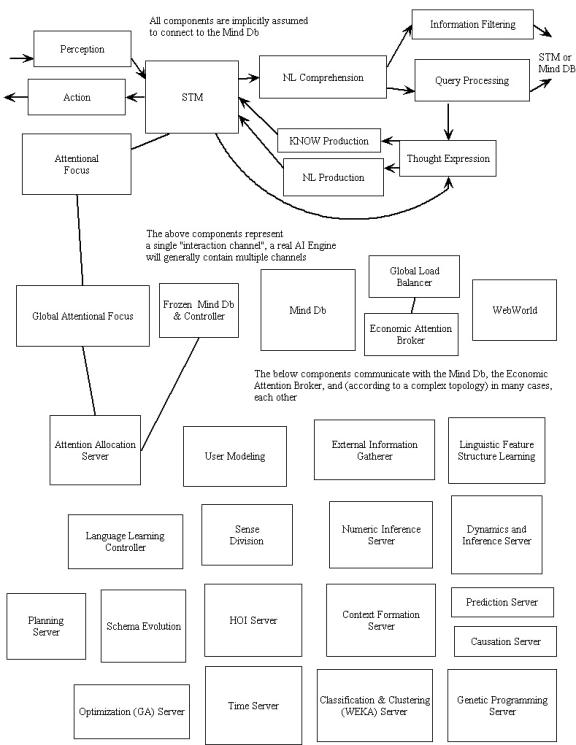
following diagram roughly summarizes the breakdown of high-level components
in the system:
Of course, a complete review of all
these parts and what they do would be far beyond the scope of this brief
article. A quick summary will have to
suffice.
Many of the components in
the above architecture diagram are based on something called the “cognitive
core.” This is a particular
collection of nodes and links and processes that embodies what we feel is the
essence of the mind, the essence of thinking. Different cognitive cores may exist in the same AI Engine, with
different focuses and biases. For
the detail-hungry reader, some deeper information about the processes
occurring in the cognitive core is given in an appendix on The Cognitive Core. The
structure and dynamics of the cognitive core is something that began in
1997-98 as a general conceptual idea with some supporting mathematics; now
it’s a precise design that has led to many empirical results. If
the cognitive core contains the essence of the mind, why do we need so many
different components, so many boxes in the diagram? The reason is specialization.
An assemblage of mental processes appropriate for perception is
different than one that’s appropriate for creative thought, which is
different from one that’s appropriate for careful reasoning or for planning
of actions. Each of the boxes in the
above diagram is a particular specialized mind-component It seems big and complicated, I’m sure. But remember -- so is the human brain, in
spite of its minimal three Similarly, all
the specialized components of Webmind operate on the same substrate, nodes
and links. Most of them are cognitive
cores with special mixes of processes.
But it’s important to have this componentized structure, to enable
reasonably efficient solution of the various problems Webmind is confronted
with. The vision of
the mind as a self-organizing actor system is upheld, but enhanced: each mind
is a self-organizing actor system that is structured in a particular way, so
that the types of actors that most need to act in various practical
situations
Good and Bad
News
After three years of work, we’ve made all these different aspects
of the mind fit together conceptually, in a wonderfully seamless way. We’ve implemented software code that
manifests this conceptual coherence.
That’s the good news. The bad news is, efficiency-wise, our experience so far indicates
that Webmind 0.5 architecture – the system we had at the end of Webmind Inc.
in March 2001 -- is probably not going to be sufficiently efficient (in
either speed or memory) to allow the full exercise of all the code that’s
been written for the cognitive core.
Thus, in the two months since the dissolution of Webmind Inc., a
furious rearchitecture of the cognitive core is has been in Essentially, the solidification of the conceptual design of the
system over the last year allows us make a variety of optimizations aimed at
specializing some of the very general structures in the current system so as
to do better at the specific kinds of processes that we are actually asking
these structures to carry out. The Now that, through this experimental process, we have learned
specifically what kinds of AI processes we want, we can morph the system into
something more specifically tailored to carry out these processes
effectively. Whether we will end up creating an entirely new codebase or
simply morphing the old one is not yet clear. Fortunately,
we do have a choice -- the architecture we constructed at Webmind Inc.,
though not efficient, In the end,
though, it’s not the code that matters anyway – it’s the design; the balance
of processes inside the cognitive core, and the division of overall system
responsibilities into components.
Each process and each component has various parameters, some of which
are important, some of which are not.
The knowledge we have gained about these processes, components and
parameters and their interactions is the most crucial thing, in terms of
working toward the rapid completion of the task of creating digital
intelligence.
Obstacles
on the Path Ahead The three
big challenges that we seem to face in moving from AI Engine 0.5 to AI Engine
1.0 ·
computational
(space and time) efficiency. ·
getting
knowledge into the system to accelerate experiential learning ·
parameter
tuning for intelligent performance We’ve
already discussed the efficiency issue and the strategic rearchitecting that
is taking place in order to address it.
Regarding
getting knowledge into the system, we are embarking on several related
efforts. Several of these involve a
formal language we have created called KNOW – a sort of logical/mathematical
language that corresponds especially well with Webmind’s internal data
structures. For example, in KNOW,
“John gives the book to Mary” might look like
[give John Mary book1 (1.0 0.9)]
[Inheritance book1 book (1.0 0.9)]
[author book1 John (1.0 0.9)] } This KNOW text is composed of three sentences. Give, inheritance
and author are relations (links), and John, Mary, book
and books are the arguments (nodes). A text in KNOW can also be
represented in XML format, which is convenient for various purposes. Our
knowledge encoding efforts include the following: ·
Conversion
of structured database data into KNOW format for import into Webmind (This is
for declarative knowledge.) ·
Human
encoding of common sense facts in KNOW ·
Human
encoding of relevant actions (both external actions like file manipulations,
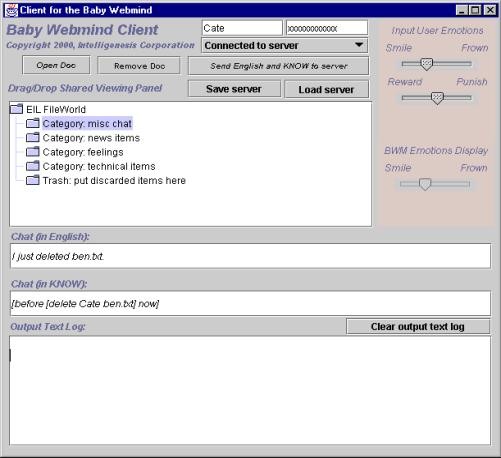
and internal cognitive actions) using “schema programs” written in KNOW ·
The
Baby Webmind [AA1]user interface, a special UI to enable
knowledge acquisition through experiential learning, to be described
below. ·
Creation
of language training datasets so that schema operating in various parts of
the natural language module can be trained via supervised learning. Regarding
parameter optimization, there have been several major obstacles to effective
work in this area so far: ·
Slowness
of the system has made the testing required for automatic parameter
optimization unacceptably slow ·
The
interaction between various parameters is difficult to sort out ·
Complexity
of the system makes debugging difficult, so that parameter tuning and
debugging end up being done simultaneously One of the
consequences of the system rearchitecture described above will be to make
parameter optimization significantly easier, both through improving system
speed, and also through the creation of various system components each
involving fewer parameters. Summing up
the directions proposed in these three problem areas (efficiency, knowledge
acquisition, and parameter tuning), one general observation to be made is
that, at this stage of our design work, analogies to the human mind/brain are
playing less and less of a role, whereas realities of computer hardware and
machine learning testing and training procedures are playing more and more of
a role. In a larger sense, what this presumably
means is that while the analogies to the human mind helped us to gain a conceptual
understanding of how AI has to be done, now that we have this conceptual
understanding, we can keep the conceptual picture fixed, and vary the
underlying implementation and teaching procedures in ways that have less to
do with humans and more to do with computers. Finally,
while the above issues are the ones that currently preoccupy us, it’s also
worth briefly noting the obstacles that we believe will obstruct us in
getting from AI Engine 1.0 to AI Engine 2.0, once the current problems are
surpassed. The key
goal with AI Engine 2.0 is for the system to be able to fully understand its
own source code, so it can improve itself through its own reasoning, and make
itself progressively more intelligent.
In theory, this can lead it to an exponentially acceleration of system
intelligence over time. The two
obstacles faced in turning AI Engine 1.0 into such a system are ·
the
creation of appropriate “inference control schema” for the particular types
of higher-order inference involved in mathematical reasoning and program
optimization ·
the
entry of relevant knowledge into the system.
The
control schema problem appears to be solvable through supervised learning, in
which the system is incrementally led through less and less simplistic
problems in these areas (basically, this means we will teach the system these
things, as is done with humans). The
knowledge entry problem is trickier, and has two parts: ·
giving
the system a good view into its Java implementation ·
giving
the system a good knowledge of algorithms and data structures (without which
it can’t understand why its code is structured as it is). Giving the
system a meaningful view into Java requires mapping Java code into a kind of
abstract “state transition graph,” a difficult problem which fortunately has
been solved by some of our friends at Supercompilers LLC
[www.supercompilers.com], in the course of their work creating a Java
supercompiler. Giving the system a knowledge of
algorithms and data structures could be done by teaching the system to read
mathematics and computer science papers, but we suspect this is a trickier
task than it may seem, because these are a specialized form of human
discourse, not as formal as they appear at first glance. In order to jump-start the system’s
understanding of scientific literature in these areas, we believe it will be
useful to explicitly encode knowledge about algorithms and data structures
into the Mizar [AA2]formalized mathematics language[11],
from which it can then be directly translated into AI Engine nodes and
links. (This is a project that we
would undertake now, if we were faced with an infinite-human-resources
situation!) Experiential
Interactive Learning
Encoding
knowledge into the system is all very well, but this can never be the primary
way a mind gains information.
Knowledge encoding is only useful as an augmentation to learning
through direct interaction with the world and with other minds -- learning
through experience. Human infants learn through experience,
and as we all know, this is a long and difficult
process. We’ve seen, in the previous
sections of this article, the incredible number of specialized mind-actors
that appear to be necessary in order to implement, within practical
computational constraints, the self-organizing system of intercreating actors
that is the mind. Given this
diversity and complexity, it’s sobering to realize that this integrated AI
Engine will not, when initially completed, be a mature mind; The experience of this AI Engine infant
will be diverse, including spidering the Web, answering user queries,
analyzing data series, and so on. But
in order for the Baby Webmind to grow into a mature and properly self-aware
system, it will need to be interacted with closely, and taught, much like a
young human. Acting and perceiving
and planning intelligently must begin on the simple “baby” level The
result of this “Baby Webmind” teaching project will be a Webmind that can
converse about what it’s doing, not necessarily with 100% English fluency nor
with the ability to simulate a human, but with spontaneity and directness and
intelligence – speaking from its own self like the real living being it
is. By that I mean we intend to
create a system that will subjectively appear intelligent and self-aware to a
majority of intelligent human beings (including computer scientists). Note
that this is not the
Turing Test, we are not seeking to fool anyone into believing that Webmind is
a human. Creating an AI system with
this kind of acting ability will be saved for later! The basic ideas of experiential
interactive learning are very general, and would apply to a Webmind with
arbitrarily diverse sense organs – eyes, ears, nose, tongue…. However we have worked out the ideas in
detail only in the concrete context of the current AI Engine, whose inputs
are textual and numerical only.
Extension of this framework to deal with music, sound, image or video
input could be accomplished fairly naturally, the difficulties being in
current computational processing limitations and file manipulation mechanics
rather than in the data structures and algorithms involved.
Baby Webmind User Interface
The Baby Webmind User Interface provides
a simple yet flexible medium within which Webmind can interact with humans
and learn from them. It has the
following components: ·
A
chat window, where we can chat with Webmind ·
Reward
and punishment buttons, which ideally should allow us to vary the amount of
reward or punishment (a very hard smack as opposed to just a plain ordinary
smack…) ·
A
way to enter in our emotions along several dimensions ·
A
way for Webmind to show us its emotions -- technically: the importance values
of some of its FeelingNode A comment on the emotional aspect is
probably appropriate here. Inputting
emotion values via GUI widgets is obviously a very crude way of getting
across emotion, compared to human facial
expressions. The same is true of Baby
Webmind’s list of FeelingNode importances: this is not really the essence of
the system’s feelings, which are distributed across its internal
network. Ultimately we’d like more
flexible emotional interchange, but for starters, I reckon this system gives
at least as much emotional interchange as one gets through e-mail and
emoticons. The next question is: what is Baby
Webmind talking to us, and sharing feelings with us, about? What world is it acting in? Initially, Baby Webmind’s world consists
of a database of files, which it interacts with via a series of operations
representing its basic receptors and actuators. It has an automatic ability to perceive files, directories,
and URL’s, and to carry out several dozen basic file operations. The system’s learning process is guided
by a basic motivational structure. Webmind
wants to achieve its goals, and its Number One goal is to be happy. Its initial motivation in making
conversational and other acts in the Baby Webmind interface is to make itself
happy (as defined by its happiness FeelingNode). The actual learning, of course, is
carried out by a combination of Webmind AI processes -- activation spreading,
reasoning, evolutionary concept creation, and so forth. These are powerful learning processes, but
even so, they can only be used to create a functional digital mind if they
are employed in the context of experiential interactive learning.
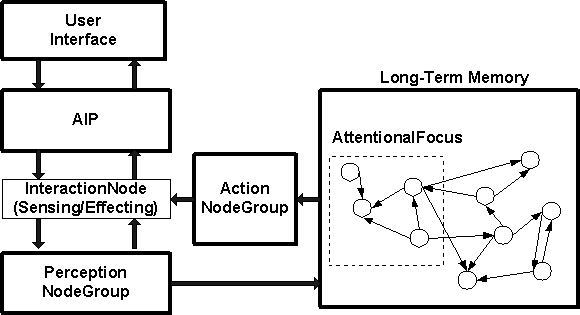
Diagram of the EIL
information workflow and major processing phases from the User
Interface to the Webmind server and back again, using our Agent Interaction
Protocol to mediate communications. How is the Happiness FeelingNode, which
ultimately guides the system’s learning process, defined? For starters, 1.
If
the humans interacting with it are happy, this increases the WAE's
happiness. 2.
Discovering
interesting things increases the WAE’s happiness 3.
Getting
happiness tokens (from the user clicking the UI’s reward button) increases
the WAE’s happiness The determinants of happiness in humans change as the human
becomes more mature, in ways that are evolutionarily programmed into the
brain. We will need to effect this in
the AI E Eventually
this process will be automated, once there are many Webmind instances being
taught by many other people and Webmind instances, but for the first time
around, this will be a process of ongoing human experimentation. Webworld One of the
most critical aspects of Webmind – schema learning, i.e. the
learning of procedures for perceiving, acting and thinking -- is also one of
the most computationally intractable.
Based on our work so far, this is the one aspect of mental processing
that seems to consume an inordinate amount of compute power. Some aspects of computational language
learning are also extremely computationally intensive, though not quite so
much so. Fortunately,
though, none of these supremely computation-intensive tasks need to be done
in real time. This means that they
can be carried out through large-scale distributed processing, across
thousands or even millions of machines loosely connected via the Net. Our system for accomplishing this kind of
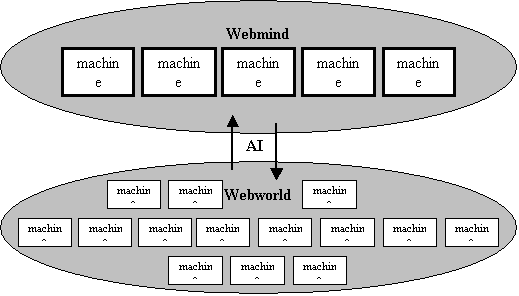
wide-scale “background processing” is called Webworld. Webworld
is an example of a peer-to-peer Internet system, more complex and powerful
than the various peer-to-peer systems that are used for file sharing
(Napster, Gnutella) and distributed problem solving (Seti @ home, distributed.net, and so
forth) today.[12] Webworld
is a sister software system to Webmind, sharing some of the same codebase,
but serving a complementary function.
A Webworld lobe is a much lighter-weight version of an AI Engine lobe,
which can live on a single-processor machine with a modest amount of RAM, and
potentially a slow connection to other machines. Webworld lobes host actors just like normal mind lobes, and
they exchange actors and messages with other Webworld lobes and with AI
Engines. AI Engines can dispatch
non-real-time, non-data-intensive “background thinking” processes (like schema
learning and language learning problems) to Webworld, thus immensely
enhancing the processing power at their disposal. Webworld is a key part of the Webmind
Inc. vision of an intelligent Internet.
It allows Webmind’s intelligence to effectively colonize the entire Net, rather than remaining
restricted to small clusters of sufficiently powerful machines As more and more people download Webworld
clients, more and more of the computer processing power in the world will be
used in the service of Webmind intelligence.
The Position of
AI in the Cosmos
We’ve
been discussing Webmind as a mind, an isolated system – reviewing its
internals. But actually this is a
limited, short-term view. Webmind
will start out as an isolated mind, but gradually, as it becomes a part of
Internet software products, it will become a critical part of the Internet,
causing significant changes in the Internet itself. To understand the potential nature of these changes, it’s useful
to introduce an additional philosophical concept, the metasystem
transition. Coined by Valentin
Turchin[13],
this refers, roughly speaking, to the point in a system’s evolution at which
the whole comes to dominate the parts.
According to current physics theories,
there was a metasystem transition in the early universe, when the primordial
miasma of disconnected particles cooled down and settled into atoms. There was a metasystem transition on earth
around four billion years ago, when the steaming primordial seas caused
inorganic chemicals to clump together in groups capable of reproduction and
metabolism. (Or, as recent
experiments suggest, perhaps this did not first happen in aerobic environments
but deep in crevasses and at high pressures and temperatures.) Unicellular life emerged, and once
chemicals are embedded in life-forms, the way to understand them is not in
terms of chemistry alone, but rather, in terms of concept like fitness, evolution,
sex, and hunger. And there was another metasystem transition when
multicellular life burst forth – suddenly the cell is no longer an autonomous
life form, but rather a component in a life form on a higher level. Note that the metasystem transition is
not an antireductionist concept, in the strict sense. The idea isn’t that multicellular
lifeforms have cosmic emergent properties that can’t be explained from the
properties of cells. Of course, if
you had enough time and superhuman patience, you could explain what happens
in a human body in terms of the component cells. The question is one of naturalness and comprehensibility, or in
other words, efficiency of expression.
Once you have a multicellular lifeform, it’s much easier to discuss
and analyze the properties of this lifeform by reference to the emergent
level than by going down to the level of the component cells. In a puddle full of paramecia, on the
other hand, the way to explain observed phenomena is usually by reference to
the individual cells, rather than the whole population – the population has
less wholeness, fewer interesting properties, than the individual cells. In the domain of mind, there are also a
couple levels of metasystem transition.
The first one is what we might call the emergence of “mind
modules.” This is when a huge
collection of basic mind components – cells, in a biological brain; “software
objects” in a computer mind – all come together in a unified structure to
carry out some complex function. The
whole is greater than the sum of the parts: the complex functions that
the system performs aren’t really implicit in any of the particular parts of
the system, rather they come out of the coordination of the parts into a
coherent whole. The various parts of the human visual
system are wonderful examples of this.
Billions of cells firing every which way, all orchestrated together to
do one particular thing: map visual output from the retina into a primitive
map of lines, shapes and colors, to be analyzed by the rest of the
brain. The best current AI systems
are also examples of this. In fact,
computer systems that haven’t passed this transition I’d be reluctant to call
“AI” in any serious sense. But, mind modules aren’t real
intelligence, not in the sense that we mean it: Intelligence as the ability
to carry out complex goals in complex environments. Each mind module only does one kind of thing, requiring inputs
of a special type to be fed to it, unable to dynamically adapt to a changing
environment. Intelligence itself
requires one more metasystem transition: the coordination of a collection of
mind modules into a whole mind, each module serving the whole and fully
comprehensible only in the context of the whole. Webmind achieves this by allowing the
interoperation of these intelligent modules within the context of a shared
semantic representation – nodes, links and so forth. Through the shared semantic representation
these different intelligent components can interact and thus evolve a
dynamical state which is not possible within any one of the modules. Like a human brain, each specialized
sub-system is capable of achieving certain complex perceptual (such as
reading a page of text) or cognitive (such as inferring causal relations)
goals which in themselves seem impressive - but when they are integrated,
truly exciting new possibilities emerge.
Taken in combination, these intelligent modules embodying systems such
as reasoning, learning and natural language processing, etc. undergo a
metasystem transition to become a mind capable of achieving complex goals
worthy of comparison to human abilities.
The resulting mind cannot be described merely as a pipeline of AI
process modules, rather it has its own dynamical properties which emerge from
the interactions of these component parts, creating new and unique patterns
which were not present in any of the sub-systems. Such a metasystem transition from
modules to mind is a truly exciting emergence. But it’s by no means the end of the line. Turchin, the conceiver of the metasystem
transition concept, proposed in his 1973 book The Phenomenon of Man: A
cybernetic approach to human evolution13
, [AA3]that the Internet and other
communication technologies had the potential to lead to a new metasystem
transition, in which humans are in some sense subordinate to an emergent
“global brain.” If
this is the case, it’s quite likely that systems like Webmind will play a
major part in the coming transition. Webmind is
part of the Web, but can also trigger self-organization in the Web as a
whole, eventually overtaking the Web and causing the Web to experience its
own Webmind-related metasystem transition.
[AA4]
As we see it, the path from the Net that
we have today to the global brain that Turchin envisioned – something that
envelops humans and machines in a single overarching superorganism --
involves at least two metasystem transitions. The
first one is the emergence of the global web mind – the transformation of the
Internet into a coherent intelligent system.
Currently the best way to explain what happens on the Net is to talk
about the various parts of the Net: particular Websites, e-mail viruses,
shopping bots, and so forth. But there will come a point when this is
no longer the case, when the Net has sufficient high-level dynamics of its
own that the way to explain any one part of the Net will be by reference to
the whole. This will come about
largely through the interactions of AI systems – intelligent programs acting
on behalf of various Web sites, Web users, corporations, and
governments will interact with each other intensively, forming something
halfway between a society of AI’s and an emergent mind whose lobes are
various AI agents serving various goals.
The traditional economy will be dead,
replaced by a chaotically dynamical hypereconomy in which there are no
intermediaries except for information intermediaries. The second metasystem transition will be the one envisioned by
Turchin and his colleages at Principia
Cybernetica -- the effective fusion of the global Web mind and the humans
interacting with it. As time goes
by, more and more of our interactions will be mediated by the global emergent
intelligent Net – every appliance we use will be jacked into the matrix;
every word that we say potentially transmitted to anyone else on the planet
using wearable cellular telephony or something similar; every thought that we
articulate entered into an AI system that automatically elaborates it and
connects it with things other humans and AI agents have said and thought
elsewhere in the world – or things other humans and AI agents are expected
to say based on predictive technology….
Architecture Diagram for an Intelligent
Internet Taking this vision one step closer to
reality, let’s look at what this might mean in terms of the Internet of the
next five years. Of course, we
realize that no such “map of the future” is likely to be extremely
accurate. The Internet is a complex
and rapidly evolving system. No one
person, company or computer program can control it. But nonetheless, we can all take part in guiding it. And in order to do this intelligently, an
overarching vision is required. The figure below is an attempt at an
“architecture diagram” for the entire Net, in its Webmind-infused form. Naturally, any diagram with such a broad
scope is going to skip over a lot of details. The point is to get across a broad global vision: First, we have a vast variety of “client
computers,” some old, some new, some powerful, some weak. Some of these access the intelligent Net through
dumb client applications – they don’t directly contribute to Internet
intelligence at all. Others have
smart clients such as WebWorld clients, which carry out two kinds of
operations: personalization operations intended to help the machines serve particular
clients better, and general AI operations handed to them by sophisticated AI
server systems or other smart clients. Next there are “commercial servers,” Finally, there is what I view as the
crux of the intelligent Internet: clusters of AI servers distributed across
the Net, each cluster representing an individual computational mind. Some of these will be Webminds, others may
be other types of AI systems. These
will be able to communicate via a common language, and will collectively
“drive” the whole Net, by dispensing problems to client machines via WebWorld
or related client-side distributed processing frameworks, and by providing
real-time AI feedback to commercial servers of various types. Some
AI servers will be general-purpose and will serve intelligence to commercial
servers using an ASP (application service provider) model; others will be
more specialized, tied particularly to a certain commercial server (e.g., Yahoo
might have its own AI cluster to back-end its portal services). Is this the final configuration for the Global Brain? No way.
Is it the only way to do things?
No. But this seems the most
workable architecture for moving things from where they are now to a
reasonably intelligent Net. After
this, the dynamics of societies of AI agents become the dominant factor, with
the commercial servers and client machines as a context. And after that…. A Path to
the Singularity The Global
Brain is a fascinating aspect of Webmind’s likely future – but it’s not the
end of the story. Another part of
the grand and fabulous future is the Singularity – a meme that seems to be on
the rise these days. The notion
of “the Singularity” is not specifically tied to AI; it was proposed in the
70’s by science fiction writer Vernor Vinge, referring to the notion that the
accelerating pace of technological change would ultimate reach a point of
discontinuity. At this point, our
predictions are pretty much useless – our technology has outgrown us in the
same sense that we’ve outgrown ants and beavers. Eliezer Yudkowsky
and Brian Atkins have founded a non-profit organization called the Singularity Institute devoted
to helping to bring about the Singularity, and making sure it’s a positive
event for humanity rather than the instantaneous end of humankind. Yudkowsky has put particular effort into
understanding the AI aspects of the singularity, discoursing extensively on
the notion of Friendly AI – the creation of AI systems that, as they rewrite
their own source code, achieving progressively greater and
greater intelligence, leave invariant the portion of their code requiring
them to be friendly to human beings. The
notion of the Singularity seems to be a valid one, and the notion of an AI
system approach it by progressively rewriting its own source code also seems
to be valid. But not all of the
details of Yudkowsky’s vision of Singularity-inducing AI seem to be
sufficiently carefully considered.
From a Webmind perspective, the following is the sequence of events
that seems most likely to lead up to the Singularity: 1)
Someone (most likely Webmind team!) creates a fairly intelligent AI,
one that can be taught, conversed with, etc. 2)
This AI is taught about programming languages, is taught about
algorithms and data structures, etc. 3)
It begins by being able to write and optimize and rewrite simple
programs 4)
After it achieves a significant level of practical software
engineering experience and mathematical and AI knowledge, it is able to begin
improving itself ... at which point the hard takeoff begins. My intuition is that, even
in this picture, the “hard takeoff” to superhuman intelligence will take a
few years, not minutes. But that's
still pretty fast by the standards of human progress. Although
his writings are not 100% clear on this point, I think that this picture of
the path to the Singularity is a little different from that of Eliezer
Yudkowsky. My sense is that he views
self-modification as entering into the picture earlier, perhaps in Stage 1,
as the best way of getting to the first "fairly intelligent
AI." I'm not 100% sure this is
wrong, but after a lot of thought I have not seen a good way to do this,
whereas I have a pretty clear picture of how to get to the Singularity
according to the steps I've outlined here.
The Singularity emerges as
a consequence of emergence-producing, dynamic feedback between Webmind and
intelligent program analysis tools like the Java supercompiler. The global brain then becomes not only
intelligent but superintelligent, and we, as part of the global brain, are
swept up into this emerging global superintelligence in ways that we can
barely begin to imagine. To cast the self-modification problem in
the language of Webmind AI, it suffices to observe that self-modification is
a special case of the kind of problem we call "schema
learning." Webmind itself is
just a big procedure, a big program, a big schema. The ultimate application of schema learning, therefore, is the
application of the system to learn how to make itself better. The complexity of the schema learning
problem, with which we have some practical experience, suggests how hard the
“self-modifying AI” problem really is.
Sure, it’s easy enough to make a small, self-modifying program. But, such a program is not
intelligent. It’s closer to being
“artificial life” of a very primitive nature. Intelligence within practical computational resources requires
a lot of highly specialized structures.
These lead to a complicated program – a big, intricate mind-schema –
which is difficult to understand, optimize and improve. Creating a simple self-modifying program and expecting it to become
intelligent through progressive environment-driven self-modification is an
interesting research program But
just because the “learn my own schema” problem is hard, doesn’t mean it’s
unsolvable. A Java or C program can
be represented as a schema in Webmind’s internal data structures, and hence
it can be reasoned about, mutated and crossed over, and so forth. This is what needs to be done, ultimately,
to create a system that can understand itself and make itself smarter and
smarter as time goes on – eliminating the need for human beings to write AI
code and write articles like this one.
Reasoning
about schema representing Java programs requires a lot of specialized
intuition, and specialized preprocessing may well be useful here, such as for
instance the automated analysis and optimization of program execution flow
being done in the Java supercompilation
project. There is a lot of work
here, but it’s a fascinating direction, and a necessary one. Grand Finale
All
of us involved in the project believe that Webmind, once fully implemented
and tested, will lead to a computer program that manifests intelligence,
according to the criterion of being able to carry out conversations with
humans that will be subjectively perceived as intelligent. It will demonstrate an understanding of
the contexts in which it is operating, an understanding of who it is and why
it is doing what it is doing, an ability to creatively solve problems in
domains that are new to it, and so forth. And of course it will
supersede human intelligence in some respects, by combining an initially
probably modest general intelligence with capabilities unique to digital
computers like accurate arithmetic and financial forecasting. All
the bases are covered in the design given here: every major aspect of the
mind studied in psychology and brain science. They’re all accomplished together, in a unified framework. It’s a big system, it’s going to demand a
lot of computational resources, but that’s really to be expected; the human
brain, our only incontrovertible example of human-level intelligence, is a
complex and powerful information-processing device. Not
all aspects of the Webmind system are original in conception, and indeed,
this is much of the beauty of the thing.
The essence of the system is the provision of an adaptable
self-reconstructing platform for integration of insights from a huge number
of different disciplines and subdisciplines.
In Webmind, The cliché Newton quote,
“If I’ve seen further than others, it’s because I’ve stood on the shoulders
of giants,” inevitably comes to mind here.
(As well as the modification I read somewhere: “If others have seen
further than me, it’s because giants were standing on my shoulders.”….) The human race has been pushing toward AI
for a long time – Webmind, if it is what I think it is, just puts on the
finishing touches. While
constructing an ambitious system like this naturally takes a long time, we
were making steady and rapid progress until Webmind Inc.’s dissolution in early 2001. It seems Arthur C. Clarke was off by a bit --
Webmind won’t be talking like HAL in the film 2001 until a bit later in the
millennium. But if the project can be rapidly
refunded, before the group of people with AI Engine expertise dissipates,
we can expect Baby Webmind’s first moderately intelligent conversations
sometime in the year 2002, and that’s going to be pretty bloody cool! Coda: Answers to Common Complaints Finally, what are the complaints and
counterarguments most often heard when discussing this project with
outsiders? First, there are those who just don’t
believe AI is possible, or believe that AI is only possible on quantum
computers, or quantum gravity computers, etc. Forget about them.
They’ll see. You can’t argue
anyone out of their religion. Science
is on the side of digital AI at this point, as has been exhaustively argued
by many people. Then there are those who feel the system
doesn’t go far enough in some particular aspect of the mind: temporal or
causal reasoning, or grammar parsing, or perceptual pattern recognition, or
whatever. This complaint usually
comes from people who have a research expertise in one or another of these
specialty areas. Webmind’s general
learning algorithms, they say, will always be inferior to the highly
specialized techniques that they know so well. My
feeling is that the current Webmind is about specialized enough. I don’t think it is so overspecialized as
to become brittle and non-adaptable, but I worry that if it becomes more
overspecialized, this will be the case.
My intuition is that things like temporal and causal reasoning should
be learned by the system as groundings of the concepts “time” and “cause” and
related concepts, rather than wired in.
On the other side, there are those who
feel that the system is “too symbolic.”
They want something more neural-nettish, or more like a simple
self-modifying system as I described in Chaotic Logic and From Complexity
to Creativity. I
can relate to this point of view quite well, philosophically. But a careful analysis of the system’s
design indicates that there is nothing a more sub-symbolic
system can do that this one can’t. This
is in fact a sub-symbolic network of procedures, differing from
an evolutionary neural net architecture only in that the atomic elements are
Boolean operators rather than threshold operators – a fairly insubstantial
difference which could be eliminated if there were reason to do so. The fact that this sub-symbolic
evolving adaptive procedure network is completely mappable into the symbolic,
inferential aspect of the system is not a bad thing, is it? I
would say that in the Webmind design we have achieved a very smooth
integration of the symbolic and subsymbolic domains, even smoother than is
likely to exist in the human brain.
This will serve WAE well in the future. There’s the complaint that Baby Webmind
won’t have a rich enough perceptual environment with just the Internet. Maybe.
Maybe we’ll need to hook up eyes and ears to it. But there’s a hell of a lot of data out
there, and the ability to correlate numerical and textual data is a good
correlate of the cross-modal sensory correlation that is so
critical to the human brain. I really
believe that this complaint is just plain old anthropomorphism. There’s the complaint that there are too
many parameters and it will take forever to get it to actually work, as
opposed to theoretically working.
This is indeed a bit of a worry, I can’t deny it. But we’ve gone a long way by testing and
tuning the individual modules of the system separately, and so far our
experience indicates that the parameter values giving optimal function for
independent activity of a mind module are generally at least acceptable
values for the activity of that mind module in an integrated Webmind
context. A
methodology of tuning parameters for subsystems in isolation, then using the
values thus obtained as initial points for further dynamic adaptation, seems
very likely to succeed in general just as it has in some special cases
already. Finally, there are those who reckon the
design is about right, but we just don’t have the processing power and memory
to run it, yet. This complaint scares
me a little bit too. But not too
much. Based on our experimentation
with the system so far, there are only two things that seem The second, real-time conversation
processing, can likely be carried out on a single supercomputer, serving as
the core of Webmind cluster. We have
a very flexible software agents system that is able to support a variety of
different hardware configurations, and we believe that by utilizing available
hardware optimally, we can make a fairly smart computer program even in
2001-2002. Of course, the more
hardware it gets, the clever it will become…. Soon enough it will be literally begging us for more, more,
more! The
Cognitive Core[<a
name="CognitiveCore"></a>]
What goes on inside the Cognitive Core, the essence
of Webmind’s digital mind? It’s not hard to list the
AI processes going on in the cognitive core: ·
Activation spreading ·
Wanderer-based link formation ·
Importance updating ·
Association finding (“halo formation”) ·
Inference (FOI and HOI) ·
Node fission/fusion and CompoundRelationNode formation ·
Schema execution ·
Context and goal formation ·
Schema learning ·
NL feature structure unification ·
Assignment of credit ·
Refreshing of STM ·
Adaptation of parameters of cognitive processes ·
Deletion and loading of nodes and links To explain what all these things mean is a little
more involved.
First,
activation spreading is simple enough.
This process cycles through all the nodes and links stored in the
mind, spreading activation according to a variant on familiar neural network
mathematics[14]. There is some subtlety here in that Webmind
contains various types of links that determine their weights in different
ways, and they need to be treated fairly.
Right here, the hybrid sub-symbolic Importance
updating is a process that determines how important each node or link is, and
thus how much CPU time it gets.
There’s a special formula for the importance of a node, based on its
activation, the usefulness that’s been gained by processing it in the recent
past, and so forth. Activation
spreads around in the network, and this causes nodes that are linked to important
nodes to tend to become important in the future – a simple manifestation of
Peirce’s Law of Mind mentioned in the main text. Wanderer-based
link formation is a process that selects pairs of nodes and, for each pair
selected, builds links of several types between them, based on comparing the
links of other types that the nodes already have. This is used to build inheritance and similarity links
representing logical relationships, and also more Hebbian-learning[15]-style
links representing temporal associations.
There are also wanderers especially designed to create links based on
higher-order reasoning: links between CompoundRelationNodes representing
logical combinations of links, and so forth.
Wanderers are guided in their wandering by links representing loose
associations between nodes. Reasoning
is a process that chooses important nodes that haven’t been reasoned on
lately, and seeks logical relations between them using the rules of uncertain
logic. Similarly, association
formation is a process that chooses important nodes and finds other nodes
that are loosely associated with them. Node
Fission/fusion picks important nodes out of the net and combines them or
subdivides them to create new nodes.
CompoundRelationNode formation, on the other hand, picks links –
relationships – out of the net and creates new nodes joining them via logical
formulas. These processes provide the
net with its creativity: they put new ideas in the system for the other
processes to act upon as they wish.
In evolutionary terms, very loosely, one might say that these
processes provide reproduction, and the other processes provide fitness
evaluation and selection based on fitness. Schema
|